This site contains student blog posts and teaching materials related to ENGL 89600/DHUM 78000: Knowledge Infrastructures, a seminar taught by Prof. Matthew K. Gold in Fall 2023 in the Ph.D. Program in English and MA Program in Digital Humanities at the CUNY Graduate Center. We will leave the content of the site available as a record of our class and a resource for others who might be interested in the topics we covered. Please contact us if you have any questions about the material that appears on the site.
When I started my dissertation research at Columbia, I discovered an exciting resource that displayed primary sources printed in England (or English) between the years 1475 and 1640 in their entirety. No longer dependent on transcripts or facsimiles which simply replicated features of the text in modern type, nor on expensive, intensive research trips during summer vacations, I was able to look at photographs of the works and see “exactly” how they appeared when first published, whenever I needed. Moreover, I could even make reproductions of the pages without writing librarians to request photographs of rare and fragile works in their special collections. All I needed were stacks of dimes and patience.
This resource, known as “Early English Books,” emerged in 1938 as the crown jewel of Eugene Power’s growing publishing company University Microfilms International. Power based his project—to photographically duplicate early British codices–on Pollard and Redgrave’s 1926 Short Title Catalogue of Early English Books, an annotated list of “English books” produced between 1475 & 1640 and housed in British collections. These included books printed in England, but also books printed elsewhere in English between those dates. “English” thus signified both the language and the nationality of the books, an unstable if ideologically productive category, then and now. While Pollard himself warned readers to take the collection as “a catalogue of the books of which its compilers have been able to locate copies, not a bibliography of books known or believed to have been produced” in the period, the list has always projected completeness through its size and relative documentary consistency.[i] Originally published in two volumes by the Bibliographical Society, a second edition with additions and corrections in three volumes took several decades to complete, emerging in 1991. In both, texts appear listed alphabetically by author with its “short title,” size (quarto, octavo etc), publisher, and date of publication (and /or date of entry in the Stationers’ Register). Occasionally, the editors included other useful but inconsistent bibliographic features of the text like typeface or two-color printing. Crucially, they also provided abbreviated lists of the major libraries in which copies could be found: these were expanded to collections outside of Britain (primarily English-speaking former colonies) with the second edition.[ii]
I knew of Pollard through his work as a “New Bibliographer” developing would-be scientific methods of textual scholarship in order to better chart the printing and production of Shakespeare’s plays, particularly the variants between Quarto and Folio editions. However, until this infrastructure project, I had no notion of Power or how the microfilm collection came about. Having turned to the STC in response to the limited holdings of early printed books in US collections, on the eve of WWII, Power convinced the institutions listed there to allow the photographing of the works as a safeguard against restricted transatlantic access and potential risk to libraries from the coming war.[i] As fears of damage to European collections grew, so did Power’s support—from the American Council of Learned Societies to the Rockefeller Foundation and eventually from U.S. intelligence departments—both “to bring microfilm copies of source materials from all parts of the world to [America]” so that “the centre of learning would shift to the United States” and increasingly to copy and send documents obtained by the OSS back to Washington. During the conflict, Power thus marshalled high-quality photographic instruments being used for wartime military reconnaissance for “Early English Books.” In turn, with its experience and contacts, Power’s company successfully continued reproducing important government documents and obtaining lucrative military commissions well into the Cold War.
Holed up on the top floor of Butler library, ironically just down the hall from Special Collections where I might have looked at some of these works in their material instantiations, I knew nothing of the military-intellectual complex that made this research possible. I focused mostly on the rolls of film, the microfilm machine reader, and the quirks of the mechanical system. The elaborate procedure for finding a book required first identifying in the printed STC the catalogue number of a specific work, and then consulting a less impressive UMI paperback that cross-listed the STC number with the number of the relevant microfilm reel. Each reel contained multiple texts and after laboriously threading the film onto the stationary reel, I’d speed-scroll towards my desired text, inevitably passing it. After some back and forth, however, the correct black-and-white images would thrillingly emerge, revealing blank pages, catchwords, prefaces, all the telling material not included in prior facsimiles. One could even save and take home a particularly interesting recto and verso,: inserting a dime in the machine’s side would produce an inky greyscale print of the viewer screen. Finally, one would rewind the film, retrieve its protective manila cuff, and place it on a cart for return to the massive metal file cabinets in the adjacent rooms. These storage units, the uniform style of the reels, and their little catalogue boxes, gave the STC a further sense of completeness, even as one discovered the gaps in the collections. In this way, New Bibliography’s positivism found support in the no-longer-futuristic promise of mid-century duplicative technologies.
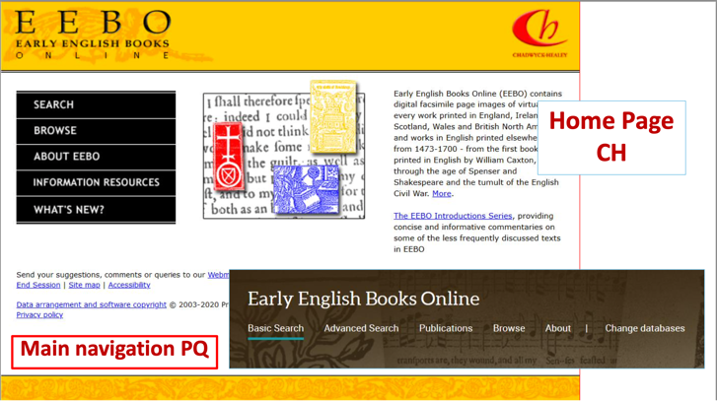
On returning to the project several years later, to prepare the book manuscript, I found a strikingly different knowledge infrastructure. Xerox had already merged with UMI’s parent company, Bell and Howell, but in 1999 Bell and Howell acquired the Chadwyck-Healey publishing group, which had started as a reprint business and then had moved from publishing research material on microfilm, to CD-Rom, and then to digital platforms. While Early English Books (now EEBOnline) had always been part of the parent company, Bell and Howell (and subsequently ProQuest) used ‘Chadwyck-Healey’ as a ‘brand’ not only for its content but also for its fine-print aristocratic associations. Accordingly, the first online databases for the STC, namely EEBO, had a mixed archaic aesthetic that included snippets of texts with ligatures and woodblock prints. When it retired the “legacy” site, ProQuest retained the serif typeface for the title but pushed the text images into the background and dimmed them, foregrounding an expanded search bar, and links to cross searches with other subsequently acquired platforms. Both the past Chadwyck-Healey and the current ProQuest home pages state that the database contains “digital facsimile page images of virtually every work printed in England, Ireland, Scotland, Wales etc etc,” or, more simply, “page images of almost every work printed in the British Isles”: each misrepresenting their comprehensiveness (particularly as not all the STC works on microfilm have been transferred to digital form, let alone transcribed into searchable text). Nonetheless, the instantaneous access to multiple works, the advanced search engines, the possibility of creating downloadable pdfs and excel sheets of bibliographic data changed not only the number of works that could be examined in a project but the questions that one could ask of them. My book history was forever transformed.
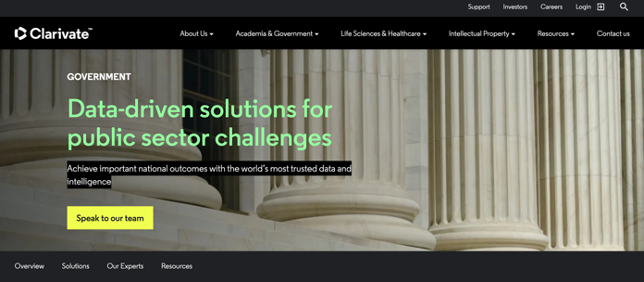
As Bell & Howell turned into ProQuest/Ex Libris, was sold to and then sold by Thomson Reuters, and ultimately became part of ClarivateTM, EEBO has become an ever smaller part of the company’s holdings and attention. Clarivate describes itself as primarily an analytics company: “We pair human expertise with enriched data, insights, analytics and workflow solutions – transformative intelligence you can trust to spark new ideas and fuel your greatest breakthroughs.” As a main provider of “Content Solutions,” ProQuest resides under the category “Academic & Government” with the stated aim of helping “researchers, faculty and students achieve success in research and learning.”[i] Yet, as Clarivate focuses increasingly on providing governments with “trusted intelligence for advanced real-world outcomes” generated through “precise insights from billions of data points ingested and normalized from thousands of sources, enriched with AI” it’s hard to see what value Early English Books will continue to hold for the megacompany. Perhaps Clarivate will retain the database out of nostalgia for and recognition of EEB’s origins in the morally questionable intertwined interests of national, military, and knowledge infrastructures which they both share, albeit technological light-years apart.[ii] If not, will I be forced to return to the Butler microfilm room? Amazingly, it still exists, although one no longer needs dimes.
[i] Like Pollard, Power emphasized the limited nature of his compendium: “The collections listed are not complete. Only those portions of particular interest to American scholars were microfilmed” (Power, 1990, Appendix C, p. 385). Cited in Mak.
[i] As with EEBO, ProQuest continues to move many Chadwyck-Healey “legacy” databases to its primary platform. However, some legacy databases have been or “will be sunsetted”—folded into other databases rather than functioning as standalone collections. In extreme cases, for example the “content in the African American Biographical database,” and “Historical Newspapers Online,” the information moves to a different database in which “much of the content from those collection [sic] has been made available in other products.” Without a detailed search, it’s hard to get a sense of what is lost in each of these transfers, but, at least for EEBO, some of the most useful (if inconsistent and idiosyncratic) bibliographic information can no longer be easily, if at all, accessed. Certainly, without access to the print volumes of the STC, users of the database will have little understanding of the group labor, primarily by women, that went into its original compilation, or into Power’s initial projects both bibliographic and military (see Mak).
[ii] “the history of the Early English Books microfilms is entangled with the history of technologies of war (Power, 1990, p. 148). The relationship also worked in the other direction: namely, the earlier success of the STC subscription service put Power in a position such that his business was able to handle copying voluminous quantities of material, and at speed, as required by the federal agencies in their wartime efforts. As a consequence, UMI was able to compete with larger outfits that included Recordak, the subsidiary of Kodak, and even outbid them on military contracts.”
I was excited to see Freire (1971) on the reading list this week. As a former public school teacher, it is a book I have had several opportunities to sit with over the years. Friere’s conceptualization of the “Banking Model” is especially well cited and continues to hold sway–I suspect because, unfortunately, there are still many teachers and professors who remain fiercely dedicated to it. At the same time, it was refreshing to think about Freire in the context of LMSs and, in a broader sense, in the shadow of the current financialization efforts taking over public education. Especially compelling in Brenden (2023), is the way that educational technology is implicated in individualizing learners while firmly placing them in isolated relationships with their teachers. This immediately conjured the image of a zoom classroom where the teacher is potentially the only person with their camera on or microphone unmuted, and where students take turns interacting with the teacher and less time interacting with each other. And of course, this dynamic is extended across the entire LMS platform, where students asynchronously log-in, submit assignments, review grades, and read feedback, all without any real need to interact with fellow students. The Friere dovetails nicely here in how this type of system becomes instructive (and part of a larger pedagogy) as it internalizes in students a willingness to adapt to an unjust world instead of critically engaging with it for the purposes of changing it (p. 74).
Source: From On Edtech’s “About” page.
The market analysis from On Edtech and eLiterate was also interesting. Both were written before the pandemic and provide coverage on the sale of Instructor to the private equity firm Thoma Bravo (one article before the sale and one after). As the author’s point out, Instructure needed to grow in order to secure its long term sustainability and profitability, which it had not done so to that point—despite its strong stock performance and large user base. To reach these goals, Instructure needed the capital to acquire smaller companies and expand services that it could then sell back to its users. In the years since the sale this is exactly what Instructure has done, going public again in 2021 while acquiring Certica Solutions, EesySoft, and Concentric Sky (the makers of Badgr).
Source: From Thoma Bravo’s landing page.
Lastly, the images pasted above caught my attention for the strategic language both companies use, both of which I found over the top and almost satirical, and which I thought people would enjoy.
DISCUSSION QUESTIONS
On page 72 Freire writes, “the interests of the oppressors lie in ‘changing the consciousness of the oppressed, not the situation which oppresses them’; for the more the oppressed can be led to adapt to that situation, the more easily they can be dominated.”
1a. What is the relevance of Friere’s “banking model,” if any, to your experiences as a student and or teacher? Does the quote above resonate with those experiences?
1b. If we are to accept Freire’s assessment of education, then who, at CUNY, might fill the role of the oppressors, and who might fill the role of the oppressed?
In the conclusion of his article, Brenden (2023, p. 308) writes, “The challenge for critical literacy is to shock education awake and to critically reflect on what we are doing and why, in both online and physical classrooms. If the LMS is here to stay, then meeting this challenge requires us to recalibrate the meaning of education, and that we ask students to pay critical attention not just to the content but also to the forms of their schooling.”
2a. Has any professor ever asked you to critically assess the digital tools and platforms you were required to use for a class (i.e., zoom, blackboard, google docs)? Or to reflect on how they have affected your learning (for better or for worse)? If so, what was your assessment?
2b. Do you agree/disagree that this work is necessary or required? Put another way, are you convinced that students need to critically assess the “forms of their schooling”?
If you were forced to speculate, what would you say is the future of online learning at CUNY? What do you imagine?
3a. What role will CUNY’s transition to Brightspace play in that future?
3b. What roles will CUNY administrators, professors, and students play in that future?
This week, we are introduced to the complexities of public higher education and more broadly, the university’s role as an infrastructure. First, Michael Fabricant and Stephen Brier play with the constant issues public education is facing because of “austerity” policies that are based on finding capital gains through the university. They give many examples to show how cost-cutting measures affect the university. Through the history of technological advancement in the university, they also discuss the effect of Open Education Resources like MOOCs which they conclude, shows that “Technological solutions are never value neutral” (198). Second, Stefano Harney and Fred Moten envision the concept of “fugitive planning” in the university. The text challenges conventional academic structures and proposes alternative ways in which critics might operate in the “undercommons”. At the backdrop is a Marxist understanding that capital production of education produces “students as problems”. They explore the possibilities of radical imagination in the academy which they envision through seven theses that all question what boundaries to freedom exist for people within the university. Theirs is a manifesto of a kind where they argue that acts that have been normalized in the university, like teaching for food have become a stagnant stage in academia. For them, the Undercommons is an alternate hidden space for resisting academic conventions, the “maroons” as fugitives who “put into question the knowledge object, let us say in this case the university, not so much without touching its foundation, as without touching one’s own condition of possibility, without admitting the Undercommons and being admitted to it” (106).
Discussion Questions:
Is the Open Education Resources Movement Western-dominated or not? Do Open Education resources best operate outside the university space where they can’t be exploited for capital gain? Does it affect the internationalization of the American University further promoting austerity blues (think: significantly higher tuition rates, VISA costs for international students)?
Moten and Harney end their chapter by pointing to the “uncanniness” of “abolition. They write, “The uncanny that disturbs the critical going on above it, the professional going on without it, the uncanny that one can sense in prophecy, the strangely known moment, the gathering content, of a cadence, and the uncanny that one can sense in cooperation, the secret once called solidarity. The uncanny feeling we are left with is that something else is there in the Undercommons” (115). What is this “something else”? Have you ever experienced the “something else” in the Undercommon? Are we working towards it and in what ways?
Brier and Fabricant say that the austerity policies in public higher education cause its underfunding. How is the money distributed within the university itself? Who faces the first budget cuts, let’s say, at CUNY? Can we also think of this with respect to LMS like Blackboard?
[PS: Sorry for posting this late. My bus was supposed to have Wifi. It didn’t]
Taking as his starting point “the emergence of computation as global infrastructure” (14), in The Stack: On Software and Sovereignty, Benjamin H. Bratton sees an opportunity to reconsider state formation and sovereignty as it was constituted in the 1648 Treaty of Westphalia, a common origin moment where political historians situate the emergence of the nation-state out of the conflicts among European proto-colonial global powers. Rather than the cartographic imaginary of the Westphalian system, Bratton posits a vertical model, based on the platform as a technology and a concept, of layers which he identifies as The Stack and ties to sedimentary patterns found variously in geology, architectural futurism, utopian political formation whether socialist or neo-liberal capitalist, and urban planning. Central to his formulation of The Stack as “less the machine of the state than the machine as state” (373), “an engine for thinking and building” (64), are the six layers he offers as model (in descending order, User, Interface, Address, City, Cloud, Earth [Fig. 3.1]) which both function “semiautonomously” (67) and in “a vertical-sectional relationship” (ibid). Spanning “computational substrates” like silica (Earth) and “server archipelagos” (Cloud), the meganetworks of City and layers that hail and interpellate the top layer of User (ie Address and Interface), Bratton’s Stack acknowledges that “computation as core infrastructure is still embryonic” (371) and yet argues that it is already present and can serve as a glimpse into geopolitical planetary futures that can be or are already being designed.
1. The Stack as stack. How essential is it that the Stack be conceived of as an (actual) (literal) stack?
2. User/Citizen/Subject position. What do you think of Bratton’s formulation of the User in his six-part structure? How is the User constituted and what pressures does this “User-subject” put on your own concepts of the human and humanism in Digital Humanities?
3. Infrastructure and the accidental. Bratton often refers to the Stack as “an accidental megastructure.” How does this notion of the accidental in the production of infrastructure, particularly on a “planetary-scale,” affect our understandings or discussions of infrastructure from this semester?
Bonus question:
4. New vocabularies: the rhetorical argument. “Today we lack adequate vocabularies to properly engage the operations of planetary-scale computation, and we make use of those at hand regardless of how poorly they serve us.” Part of Bratton’s project seems to be to provide a new vocabulary for the phenomenon of computation as governance: how helpful do you find the particulars of his glossary? What terms seem to allow a new understanding, theorization, or ability to “map. . . interpret . . . and redesign” what he identifies as “this computational and geopolitical condition”? Do you find his particular rhetorical tropes—eg: chiasmus: —useful as analytic tools? (See for example, p. 57: “As a platform to be read and interpreted, The Stack clearly sits on both sides of this coupling of culture and technology. It relies on software as both a kind of language and a kind of technology, of algorithms of expression and the expressions of algorithms, . . . .”)
This week’s readings cut through the technical jargon surrounding “software platforms” describing them as intermediary, second-order infrastructures that build upon physical infrastructures that usually take between thirty and one hundred years to fully develop. According to Edwards, such platforms (for example Facebook and YouTube) spread across the globe like wildfire due to their strategic architectural features which allow the platform’s core components to interface with new and innovative complementary components as needed. A defining feature of these platforms is that they position themselves as neutral spaces for user activity, “what we might call ‘platform discourse’ is to render the platform itself as a stable, unremarkable, unnoticed object, a kind of empty stage” (Edwards 319). Kurgan et al., however, contend in “Homophily” using Facebook’s example that the way these platforms operate is far from neutral. Social networks like Facebook group people with similar interests, showing them friend suggestions and content based on their interests only thereby creating a feedback loop that doesn’t allow for diverse viewpoints or knowledge. Such algorithmic practices on a large scale over time lead to polarization with these software platforms having a very real impact on societal and cultural perceptions. Showing users only content that they like while ignoring the adverse impact that has on society at large is because user activity on these platforms yields raw material in the form of data. According to Srnicek, capitalism in the twenty-first century is centered around the extraction and use of data for advertising purposes, worker optimization, etc. Platforms are so important now because they facilitate the collection of this data.
Question One: In Platform Capitalism Srnicek notes that advertising platforms sell users’ online activities to adeptly matched advertisers to sell consumers more products. Has there ever been a case where the data from these software platforms was used to specifically create products that match users’ needs instead of just selling them existing products? Would data extraction be a less exploitative process if that information was used to create products based on trends that indexed what consumers wanted?
Question Two: In the Age of Surveillance Capitalism Zuboff contends that surveillance capitalism was invented in the US though the consequences now belong to the world. Considering his “no exist” metaphor, would Gen Z outside the US in less developed countries like Kenya and Ghana have more of a backstage to nurture the self since these platforms would not be used as readily there due to technological limitations/internet issues as they would have been in the US?
Question Three: Srnicek points out that now companies like Amazon and Microsoft own the software instead of the physical product allowing them to employ a subscription model for their users. Considering these subscription services necessitate continuous internet access would people in developing countries be at a disadvantage because of such a requirement? Could not owning a product for indefinite use—as opposed to the subscription model—hinder people from less technologically advanced regions from making use of it?
One of the key insights common to all arguments is that there is a correlation between the concept of race and technological elements that go beyond just issues of access to computers, resources, etc. This week, we were introduced to methods of reading formats within technology parallel to the rise of the theorization of race. First, Biewen and Kumanyika provide context about the origin of the concept of race, its rootedness in Western Imperialism, its biological inaccuracy, and its prevailing realness in society. Through a historical overview of travel chronicles from Greek writer Herodotus, Moroccan traveler Ibn Battuta, and enlightenment thinkers Linnaeus and Blumenbach, they show how while “race” is a fairly recent term, due to socioeconomic gains, societies have always maintained biases against Other communities within themselves. Kumanyika concludes by iterating on the need to understand the underlying causes for the perpetuation of dehumanizing narratives against people of color. Second, McPherson picks up on issues of computation and devises an interesting parallel between the “modular” format of operating systems like UNIX (UNiplexed Information Computing System) and the “lenticular logic” in post-civil war USA both of which follow a system of disconnection and decontextualization. Postulating their argument as a conceptual framework for digital scholars, McPherson writes that we need to be aware of and somehow attempt to undo the “fragmentary knowledges encouraged by many forms and experiences of the digital [that] neatly parallel the logics that underwrite the covert racism endemic to our times, operating in potential feedback loops, supporting each other”. Third, Johnson introduces the idea of “markup bodies” to state the methodologies employed by black digital scholars as they attend to the descendants of enslaved people and provide attention to their narratives. Johnson writes with a critique of data arguing that “Black digital practice requires researchers to witness and remark on the marked and unmarked bodies, the ones that defy computation, and finds ways to hold the null values up to the light” (71-72). Finally, Ghorbaninejad, Gibson, and Wrisley decode a case study of the lack of programming tools, UI/UX design precision, and metadata settings, of right-to-left (RTL) languages like Arabic, Urdu, etc. They argue that because the RTL DH scholarship is distanced from academia in the Global North and provides little to no financial incentive to most DH scholars in the West, “Digital humanists must become advocates for broad-level RTL integration” (63). Overall, studying the technological backgrounds of racialized knowledge infrastructures allows us to question what an interdisciplinary perspective means i.e. how the “digital” and the “humanities” really work together. It urges us to ask how can we critique knowledge infrastructures when their seemingly “invisible” technical operations systematically influence our understanding of “race” today.
For me, I was deeply invested in the abundance of technical information in these texts, something I am new to as a scholar of English. So, I ask these questions:
McPherson traces the similarities in form between computational systems like UNIX/relational databases, and the liberal perception of “race” using the “Rule of Modularity” i.e. the separation of parts of a code into workable sections. She argues that computational systems and cultural imaginaries born in the 1960s “mutually infect one another”. To many scholars in the humanities aware of the Sokal affair, McPherson’s argument can seem a bit radical. Similar to the defense of “black boxing” in supply chains, digital technocrats might argue that “modularity” is necessary to produce simplicity during coding. Does our specialization in a particular academic department make us less susceptible to interdisciplinary arguments like these? How might our lack of interdisciplinary knowledge (eg. many DH scholars not being coders) affect our judgment of racial infrastructures?
Kumanyika ends the podcast by saying, “You know, I’ve seen things on race, like they pull Kanye, they might pull Shaquille O’Neal, like hey why are you interviewing these people to talk about race? It’s not their thing.” Do we need “experts” to talk about race? Can’t any person of color have the right to speak critically about race or is a certain mode of knowledge necessary? In other words, are knowledge infrastructures “invisible” only to a few?
Ghorbaninejad et al. argue that contemporary content in RTL languages seems to contain less “value” than LTR in the Global North today. In order to sustain RTL scholarship, they recommend Internationalization followed by Localization where “software is first designed to be locale-indifferent before it is localized to meet the regional, linguistic/cultural, and technical requirements of each locale” (55). Can we think of any examples where software is Internationalized but not Localized causing what the authors fear causes “cultural mistranslation.” Further, should the responsibility fall on people to whom the culture is “local” to produce such software? Do issues like funding further complicate this possibility?
Most of the readings this week recommend advocacy from the DH scholar. What does advocacy look like for you?
For Jhonson, “data” is the “objective and independent unit of knowledge”. It also signifies “the independent and objective statistical fact as an explanatory ideal party to the devastating thingification of black women, children, and men” (58). What might Jhonson say are the ethical challenges for “quantitative” digital studies like sentiment analysis or geospatial analysis?
The introduction to Global Debates in the Digital Humanities offers useful contours of some debates and issues at stake for studying digital humanities in the Global South. It’s useful that Fiormonte, Chaudhari, and Ricaurte offer a definition of the Global South: not just a geographical entity but “symbolically” as places that are located at the economic, cultural, and social margins of the industrialized world. Although it’s not the authors’ goal to define DH, rethinking DH within the Global South asks us to reflect more broadly on the term “digital humanities” itself — what do we mean by it and what does it include — as there are “no unique terms for defining digital humanities” in other languages like Chinese. One particular issue that the three readings from Global Debates in the Digital Humanities grapple with is language — as a means by which Western hegemony continues to maintain itself in producing, controlling, and regulating knowledge. This is an issue of “epistemic sovereignty” regarding the dominance of the English language in producing and disseminating knowledge. As the readings point out, the English-speaking North is the center for creating and diffusing academic knowledge, which is based on “the inequalities inherent in [its] infrastructures for the production and diffusion of knowledge.” For example, the US and the UK publish more journals than the rest of the world combined. Interestingly, Fiormonte, Chaudhari, and Ricaurte also share the challenges of finding contributors to the book to cover as many geographic areas as possible. They had a multilingual call for papers (for regions like Africa, the Middle East, and the Caribbean), but there weren’t a lot of proposals.
So I was thus wondering: 1. Do you think an “epistemic solidarity” can be achieved if scholars and researchers encounter epistemic (but also infrastructural, political, and economic) differences and “injustices”?
Sayan Bhattacharyya likewise takes up the issue of language and ill/legibility in “Epistemically Produced Invisibility” in conjunction with the issue of scale effects and network effects. Different forms of knowledge, especially from the Global South, which are more heterogeneous (produced on a different scale, in a different language, etc), are rendered illegible. He discusses that an attempt to address the issue of “epistemically produced invisibility” relies on the task of searching for a “common language” or “framework” that does not reduce or overlook epistemically-heterogeneous data, which becomes illegible under forces and tools of standardization. He proposes the “logics of hierarchal and nonhierarchical production and accumulation.” My questions regarding Bhattacharyya’s piece are more impressionistic:
2. What do you make of the concept/term “cognitive capitalism”? In light of our discussion of knowledge monetization and gigantic corporations that dominate multiple information markets like RELX and Thomas Reuters last week, how is a “nonhierarchical production and accumulation” of knowledge possible?
3. Bhattacharyya ends the chapter by talking about a tool he uses in his undergraduate classes in the humanities called “persistent annotation,” which asks students to annotate the invisibilities/illegibilities. Have you encountered any tool like this in your academic career? Could you think of other tools/approaches to address “epistemologically produced invisibility” in the classroom?
4. Gimena del Rio Riande’s “Digital Humanities and Visible and Invisible Infrastructures” highlights the materiality and infrastructure of digital humanities, which is germane to our ongoing class discussions. Riande talks about her experience with having no support from the institution when doing DH research. She learns how “collaboration could be carried out horizontally at grassroots level.” This makes me wonder about the extent to which organizations like the Alliance of Digital Humanities Organization help address the issue of infrastructure and resource scarcity in academic publications in the field of DH – what measures could/would they take?
5. Riande ends the chapter by invoking Geoffrey Rockwell’s assertion that “Infrastructure IS people.” What do you make of this? Do you think the people aspect is already inscribed within the concept of infrastructure? Or it is necessary to emphasize the “people” aspect of infrastructure so that a certain aspect, such as its entanglement with labor, can be more accentuated?
In this week’s readings, we see that the democratic ideal of the knowledge commons grows complicated as open access publishing platforms are increasingly targeted by information capitalism. Lamdan, Kember & Brand, and Aspesi et al. all highlight the relationship between open access scholarship and data analytics: as academic publishing proves less and less profitable, companies that once distributed research are now finding financial success in privatizing and paywalling information that was created under public funding; mining data from their users; and interpreting user data to generate predictions about academic futures, lucrative research investments, and even public engagement with government systems. Kember & Brand offer an optimistic solution to the “corporate capture of open access publishing” by advocating for cross-institutional collaboration and non-profit, non-commercial publishing platforms. However, Lamdan’s book reveals the overwhelming ubiquity of the “data cartels” that undergird the world of information media, essentially making any separation between knowledge and capital impossible. Lamdan identifies two companies — Thomson Reuters and RELX — as the leading data analytics conglomerates behind the push to privatize information at the expense of public cost, safety, and freedom. Within the RELX group, Aspesi et al. focus part of their article on the academic publisher Elsevier, which exemplifies the ability of private publishing companies to control knowledge production through their insider-trading-like access to industry professionals, funding decisions, and university hiring practices.
After reading the preface and opening chapter of Lamdan’s Data Cartels: The Companies that Control and Monopolize our Information, I was horrified by the power of companies like Thomson Reuters and RELX to transform our data into profit; and disturbed by the links between personal information and systemic violence enacted through surveillance. I wanted to know how these infamous data cartels presented themselves, and visited the Thomson Reuters website. On a recent job posting for “Associate Client Executive, FindLaw”, the company confidently states: “We have a superpower that we’ve never talked about with as much pride as we should – we are one of the only companies on the planet that helps its customers pursue justice, truth and transparency. Together, with the professionals and institutions we serve, we help uphold the rule of law, turn the wheels of commerce, catch bad actors, report the facts, and provide trusted, unbiased information to people all over the world.” This characterization of Thomson Reuters’s work counters some of Lamdan’s most revelatory explanations of the company’s use of data: there is no mention of ICE, “double dipping” information, inaccurate criminal and arrest records, or prescriptive insurance policies. From Lamdan’s book, I got the impression that companies like Thomson Reuters actively do not want their customers to pursue justice, truth, and transparency — unless the company itself is the one dictating what is just, true, and transparent. Contained within Thomson Reuters’s hubristic self-assessment, I did find a kernel of truth: through their overwhelming, inextricable social and political influence, data cartels do have the power to “uphold the rule of law”, “turn the wheels of commerce”, and “provide […] information to people all over the world”. And what a terrifying thought that is…
Question 1: In their piece on “The Corporate Capture of Open-Access Publishing”, Sarah Kember and Amy Brand propose a safeguard to the future of public knowledge: “More international collaboration, including linked university repositories and, potentially, state-owned, noncommercial platforms, is also needed to turn the false promise of “openness” into truly public knowledge.” Do you think that cross-institution collaboration can be successful, even as academic institutions compete for funding and research breakthroughs? What should the role of the state be in creating and circulating public knowledge?
Question 2: Sarah Lamdan points out that old regulatory laws are not equipped to limit the monopoly that data cartels have on the public’s access to information (Lamdan, 22). Similarly, are information piracy and theft laws commensurate to the act of releasing paywalled or privatized information to the public? What have cases like United States v. Swartztaught us about making public information accessible through illegal channels?
Question 3: The SPARC Landscape Analysis report ends with suggestions for mitigating the risks inherent to the movement of commercial publishers into the heart of academic institutions. “Risk mitigation” would take the form of “actions aimed at protecting colleges and universities from the unintended consequences of deploying a rising number of data analytic tools and collecting larger and more intrusive amounts and categories of data.” Recalling our discussions on infrastructure, how do you imagine a “risk mitigation infrastructure” could look at CUNY? How would checks and balances be implemented to protect the CUNY community’s personal data and intellectual property? Which existing university offices would be tasked with handling the data analytics companies; or what roles would need to be created to do so?
Academic journals are supposed to help in the dissemination of knowledge through the publication of high-quality research. Such scholarship, however, is often behind paywalls for example the Modern Language Quarterly, PMLA, and the South Atlantic Quarterly are all journals that need subscriptions or university access to read the texts hosted on their platforms. According to the Duke library website, the average cost for one highly cited article for “an unaffiliated researcher is $33.41” (“Library 101 Toolkit”). This makes research, especially for budding academics not associated with a university library, an expensive endeavor. This is where open-access journals come in. Open-access journals allow free and immediate use of academic books, articles, and other texts without access fees “combined with the rights to use these outputs fully in the digital environment” (“Springer Nature”).
The Journal of Cultural Analytics is one such online open-access journal dedicated to promoting scholarship that applies “computational and quantitative methods to the study of cultural objects (sound, image, text), cultural processes (reading, listening, searching, sorting, hierarchizing) and cultural agents (artists, editors, producers, composers)”. It published its first issue in 2016 featuring three sections: articles that offer peer-reviewed scholarship, data sets about discussions associated with new data related to cultural studies, and debates regarding key interventions surrounding the computational study of culture. This open-access journal aims to “serve as the foundational publishing venue of a major new intellectual movement” and challenge disciplinary boundaries (“Journal of Cultural Analytics”). It allows authors to retain the copyright of their published material and grants itself the right of first publication with their work under the Creative Commons Attribution 4.0 International License (CCBY). Due to its open-access model, authors do not get paid for publishing with it. One of its very first articles, “There Will Be Numbers” by Andrew Piper has to date garnered 2852 views and 602 PDF downloads (“Journal of Cultural Analytics”).
This journal is published by McGill University’s Department of Languages, Literatures, and Cultures. Its editor is Andrew Piper, a professor at McGill’s Languages and Literatures department and director of the Cultural Analytics lab. Its remaining editorial board is made up of digital humanities professors from across different North American universities such as UT Austin, Cornell, CUNY etc. Despite its affiliation with McGill, this journal is hardly ever mentioned in the university’s halls nor are students made aware of its existence. The most I heard about it was in my “Introduction to Digital Humanities” seminar when one of my class readings was from this journal. Thus, there seems to be almost no effort on McGill’s part to promote this journal to students. Delving deeper into this issue, the problem seems to be that despite its interdisciplinary nature this journal is viewed as catering to a niche audience i.e., digital humanists and not all humanities scholars. Considering it is published by a particular humanities department at McGill instead of in collaboration with all such programs might explain why it is less known and promoted. As an open-access journal, especially one in a computational humanities field, it should be better advertised to students at least in the university that publishes it so that they may better avail its resources.
Need help with the Commons?
Email us at [email protected] so we can respond to your questions and requests. Please email from your CUNY email address if possible. Or visit our help site for more information: